
By Daniel Greenfield
The future of ‘standard’ medical practice might be here sooner than anticipated, where a patient could see a computer before seeing a doctor. Through advances in artificial intelligence (AI), it appears possible for the days of misdiagnosis and treating disease symptoms rather than their root cause to move behind us. Think about how many years of blood pressure measurements you have, or how much storage you would need to delete to fit a full 3D image of an organ on your laptop? The accumulating data generated in clinics and stored in electronic medical records through common tests and medical imaging allows for more applications of artificial intelligence and high performance data-driven medicine. These applications have changed and will continue to change the way both doctors and researchers approach clinical problem-solving.
However, while some algorithms can compete with and sometimes outperform clinicians in a variety of tasks, they have yet to be fully integrated into day-to-day medical practice. Why? Because even though these algorithms can meaningfully impact medicine and bolster the power of medical interventions, there are numerous regulatory concerns that need addressing first.
What makes an algorithm intelligent?
Similar to how doctors are educated through years of medical schooling, doing assignments and practical exams, receiving grades, and learning from mistakes, AI algorithms also must learn how to do their jobs. Generally, the jobs AI algorithms can do are tasks that require human intelligence to complete, such as pattern and speech recognition, image analysis, and decision making. However, humans need to explicitly tell the computer exactly what they would look for in the image they give to an algorithm, for example. In short, AI algorithms are great for automating arduous tasks, and sometimes can outperform humans in the tasks they’re trained to do.
In order to generate an effective AI algorithm, computer systems are first fed data which is typically structured, meaning that each data point has a label or annotation that is recognizable to the algorithm (Figure 1). After the algorithm is exposed to enough sets of data points and their labels, the performance is analyzed to ensure accuracy, just like exams are given to students. These algorithm “exams” generally involve the input of test data to which programmers already know the answers, allowing them to assess the algorithms ability to determine the correct answer. Based on the testing results, the algorithm can be modified, fed more data, or rolled out to help make decisions for the person who wrote the algorithm.
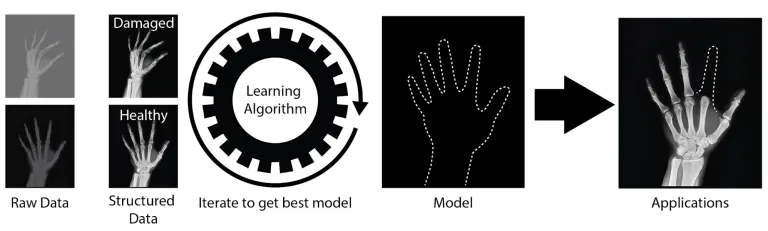
Figure 1: AI algorithms. The above image shows an example of an algorithm that learns the basic anatomy of a hand and can recreate where a missing digit should be. The input is a variety of hand x-rays, and the output is a trace of where missing parts of the hand should be. The model, in this case, is the hand outline that can be generated and applied to other images. This could allow for physicians to see the proper place to reconstruct a limb, or put a prosthetic.
Recent Applications of AI in Medicine
Advances in computational power paired with massive amounts of data generated in healthcare systems make many clinical problems ripe for AI applications. Below are two recent applications of accurate and clinically relevant algorithms that can benefit both patients and doctors through making diagnosis more straightforward.
The first of these algorithms is one of the multiple existing examples of an algorithm that outperforms doctors in image classification tasks. In the fall of 2018, researchers at Seoul National University Hospital and College of Medicine developed an AI algorithm called DLAD (Deep Learning based Automatic Detection) to analyze chest radiographs and detect abnormal cell growth, such as potential cancers (Figure 2). The algorithm’s performance was compared to multiple physician’s detection abilities on the same images and outperformed 17 of 18 doctors.
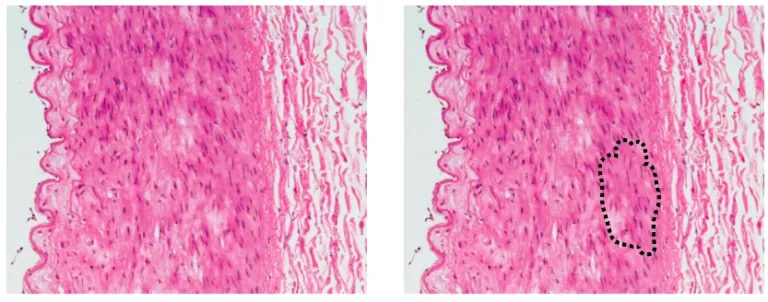
Figure 2: Applications of AI algorithms in medicine. The left panel shows the image fed into an algorithm. The right panel shows a region of potentially dangerous cells, as identified by an algorithm, that a physician should look at more closely.
The second of these algorithms comes from researchers at Google AI Healthcare, also in the fall of 2018, who created a learning algorithm, LYNA (Lymph Node Assistant), that analyzed histology slides stained tissue samples) to identify metastatic breast cancer tumors from lymph node biopsies. This isn’t the first application of AI to attempt histology analysis, but interestingly this algorithm could identify suspicious regions undistinguishable to the human eye in the biopsy samples given. LYNA was tested on two datasets and was shown to accurately classify a sample as cancerous or noncancerous correctly 99% of the time. Furthermore, when given to doctors to use in conjunction with their typical analysis of stained tissue samples, LYNA halved the average slide review time.
Recently, other imaging-based algorithms showed a similar ability to increase physician accuracy. In the short term, these algorithms can be used by doctors to assist with double-checking their diagnoses and interpreting patient data faster without sacrificing accuracy. In the long term, however, government approved algorithms could function independently in the clinic, allowing doctors to focus on cases that computers cannot solve. Both LYNA and DLAD serve as prime examples of algorithms that complement physicians’ classifications of healthy and diseased samples by showing doctors salient features of images that should be studied more closely. These works exemplify the potential strengths of algorithms in medicine, so what is holding them back from clinical use?
Regulatory Implications and Algorithm Limitations Going Forward
Thus far, algorithms in medicine have shown many potential benefits to both doctors and patients. However, regulating these algorithms is a difficult task. The U.S. Food and Drug Administration (FDA) has approved some assistive algorithms, but no universal approval guidelines currently exist. On top of that, the people creating algorithms to use in the clinic aren’t always the doctors that treat patients, thus in some cases, computationalists might need to learn more about medicine while clinicians might need to learn about the tasks a specific algorithm is or isn’t well suited to. While AI can help with diagnosis and basic clinical tasks, it is hard to imagine automated brain surgeries, for example, where sometimes doctors have to change their approach on the fly once they see into the patient. In this way and others, the possibilities of AI in medicine currently outweigh the capabilities of AI for patient care. Clarified guidelines from the FDA, however, could help specify requirements for algorithms and could result in an uptick of clinically deployed algorithms.
Furthermore, the FDA has strict acceptance criteria for clinical trials, requiring extreme transparency surrounding scientific methods. Many algorithms rely on very intricate, difficult to deconvolute mathematics, sometimes called a ‘black box’, to get from the input data to the final result. Would the inability to ‘unpack the black box’ and clarify the inner workings of an algorithm impact the likelihood that the FDA will approve a trial that relies on AI? Probably. Understandably, researchers, companies, and entrepreneurs might be hesitant to expose their proprietary methods to the public, at the risk of losing money by getting their ideas taken and strengthened by others. If patent laws change from their current state, where an algorithm is technically only patentable if part of a physical machine, the ambiguity surrounding algorithm details could lessen. Either way, increasing transparency in the short term is necessary so that patient data is not mishandled or improperly classified, and so it could be easier to determine whether an algorithm will be sufficiently accurate in the clinic.
In addition to obstacles for FDA approval, AI algorithms may also face difficulties in achieving the trust and approval of patients. Without there being a clear understanding of how an algorithm works by those approving them for clinical use, patients might not be willing to let it be used to help with their medical needs. If forced to choose, would patients rather be misdiagnosed by a human or an algorithm, if the algorithm generally outperforms physicians? This is a tough question for many to answer but probably boils down to feeling confident in an algorithm’s decision making. Correct decision making is a function of the structure of the data used as input, which is vitally important for correct functionality. With misleading data, the algorithms can give misleading results. It is quite possible that individuals creating an algorithm might not know that the data they feed is misleading until it is too late, and their algorithm has caused medical malpractice. This error can be avoided by both clinicians and programmers being well informed about the data and methods needed to use data correctly in the algorithm. By establishing relationships between clinicians that understand the specifics of the clinical data and the computationalists creating the algorithms, it’ll be less likely for an algorithm to learn to make incorrect choices.
Proper understanding of the limitations of algorithms by clinicians and proper understanding of clinical data by programmers is key to creating algorithms usable in the clinic. It might be necessary for companies to sacrifice the secrets of their algorithm’s functionality so that a more widespread audience can vet the methods and point out sources of error that could end up impacting patient care. We still seem to be far from algorithms independently operating in clinics, especially given the lack of a clear pathway for clinical approval. Defining the qualities necessary for an algorithm to be deemed sufficiently accurate for the clinic, while addressing the potential sources of error in the algorithm’s decision making, and being transparent about where an algorithm thrives and where it fails, could allow for public acceptance of algorithms to supplant doctors in certain tasks. These challenges, however, are worth trying to overcome in order to universally increase the accuracy and efficiency of medical practices for various diseases.